NAME
App::Greple::xlate - greple 的翻译支持模块
SYNOPSIS
greple -Mxlate::deepl --xlate pattern target-file
greple -Mxlate::gpt4 --xlate pattern target-file
greple -Mxlate --xlate-engine gpt4 --xlate pattern target-fileVERSION
Version 0.9912
DESCRIPTION
Greple xlate 模块查找所需的文本块并将其替换为翻译后的文本。目前,DeepL(deepl.pm)和ChatGPT 4.1(gpt4.pm)模块已作为后端引擎实现。
如果你想翻译以 Perl 的 pod 风格编写的文档中的普通文本块,请使用 greple 命令,并结合 xlate::deepl 和 perl 模块,如下所示:
greple -Mxlate::deepl -Mperl --pod --re '^([\w\pP].*\n)+' --all foo.pm在此命令中,模式字符串 ^([\w\pP].*\n)+ 表示以字母数字和标点符号开头的连续行。该命令会高亮显示需要翻译的区域。选项 --all 用于输出完整文本。
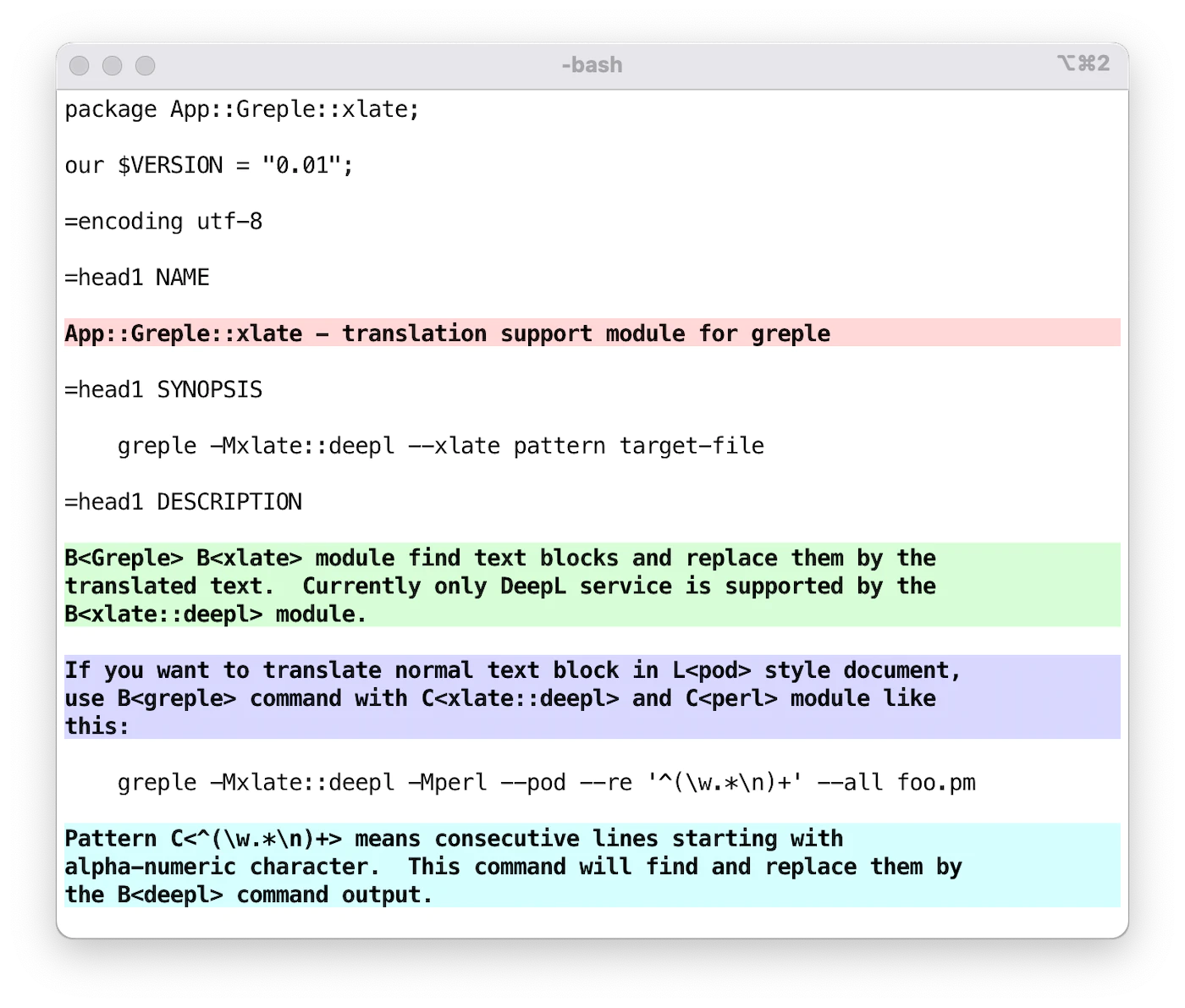
然后添加 --xlate 选项以翻译选定区域。这样,它会找到所需的部分,并用 deepl 命令的输出替换它们。
默认情况下,原文和译文以与 git(1) 兼容的“冲突标记”格式输出。使用 ifdef 格式,可以通过 unifdef(1) 命令轻松获取所需部分。输出格式可通过 --xlate-format 选项指定。
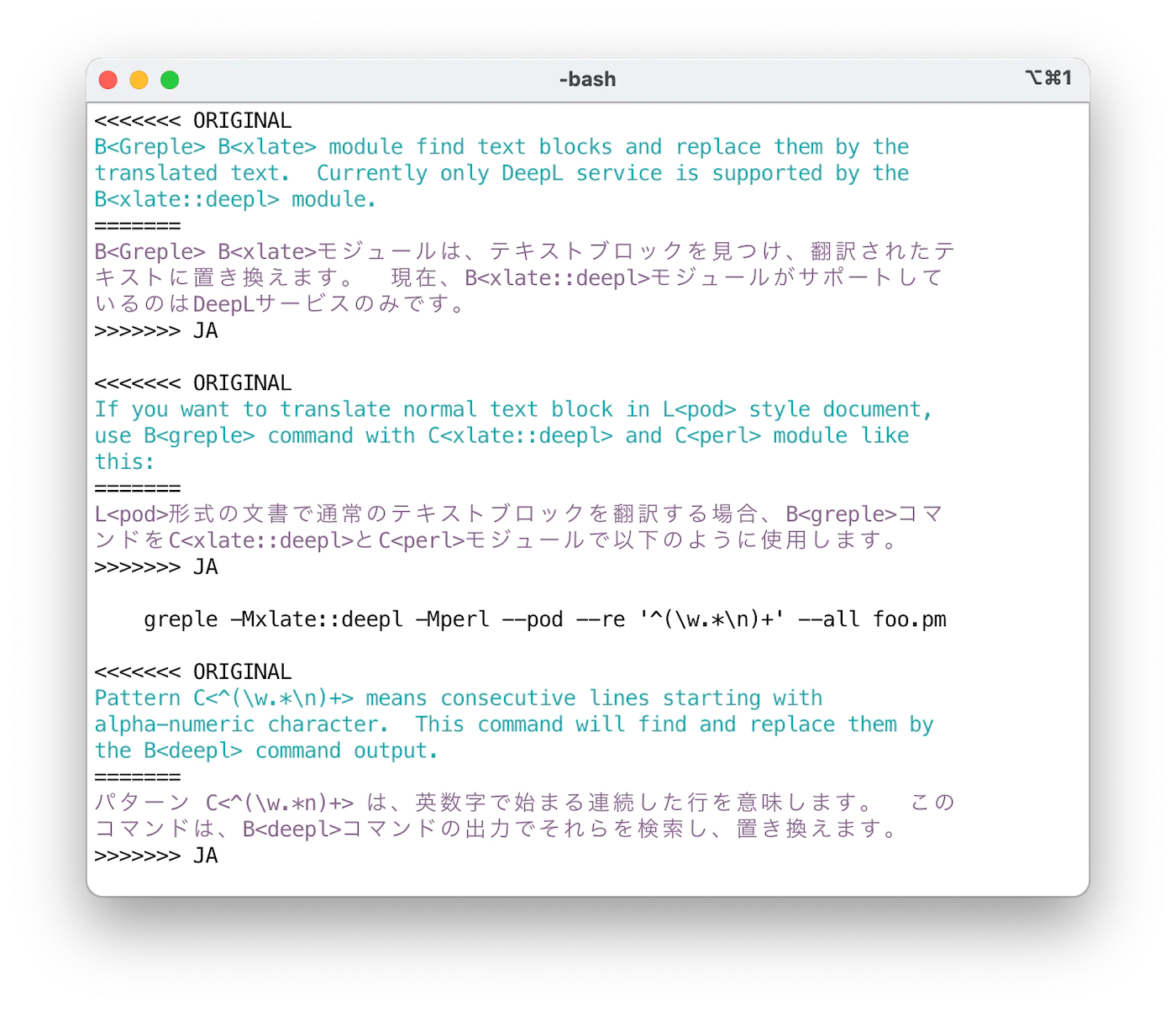
如果你想翻译全部文本,请使用 --match-all 选项。这是指定匹配整个文本的模式 (?s).+ 的快捷方式。
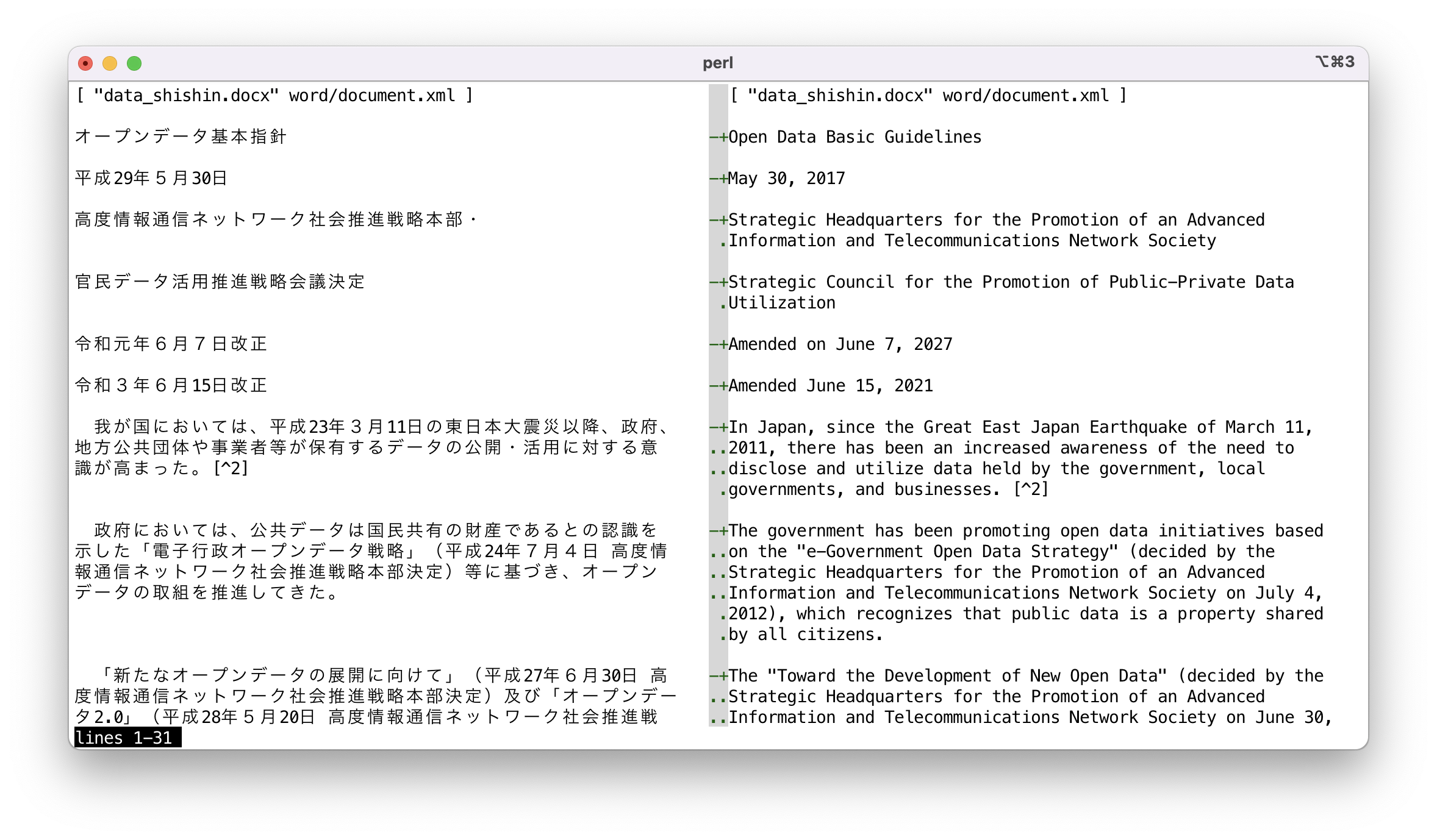
冲突标记格式的数据可以通过 sdif 命令配合 -V 选项以并排样式查看。由于逐字符串比较没有意义,建议使用 --no-cdif 选项。如果不需要为文本着色,请指定 --no-textcolor(或 --no-tc)。
sdif -V --no-filename --no-tc --no-cdif data_shishin.deepl-EN-US.cm
NORMALIZATION
处理是按指定单元进行的,但对于多行非空文本的序列,会将它们合并为一行。该操作按如下方式执行:
去除每行开头和结尾的空白字符。
如果一行以全角标点符号结尾,则与下一行连接。
如果一行以全角字符结尾,且下一行以全角字符开头,则将两行连接。
如果一行的结尾或下一行的开头不是全角字符,则在连接时插入一个空格字符。
缓存数据是基于规范化文本管理的,因此即使进行了不影响规范化结果的修改,缓存的翻译数据仍然有效。
此规范化过程仅对第一个(第 0 个)和偶数编号的模式执行。因此,如果如下指定两个模式,匹配第一个模式的文本将在规范化后处理,而匹配第二个模式的文本则不会进行规范化处理。
greple -Mxlate -E normalized -E not-normalized因此,对于需要将多行合并为一行处理的文本,请使用第一个模式;对于预格式化文本,请使用第二个模式。如果第一个模式没有匹配的文本,请使用如 (?!) 这样不会匹配任何内容的模式。
MASKING
有时,您可能不希望翻译文本的某些部分。例如,markdown 文件中的标签。DeepL 建议在这种情况下,将不需要翻译的部分转换为 XML 标签,翻译后再还原。为支持此功能,可以指定需要屏蔽翻译的部分。
--xlate-setopt maskfile=MASKPATTERN这会将文件 `MASKPATTERN` 的每一行解释为正则表达式,翻译匹配的字符串,并在处理后还原。以 # 开头的行会被忽略。
复杂的模式可以用反斜杠转义换行符分多行书写。
可以通过 --xlate-mask 选项查看屏蔽后文本的变化。
此接口为实验性,未来可能会有变动。
OPTIONS
- --xlate
- --xlate-color
- --xlate-fold
- --xlate-fold-width=n (Default: 70)
-
对每个匹配区域调用翻译过程。
如果不使用此选项,greple 会作为普通搜索命令运行。因此,您可以在实际翻译前检查文件中哪些部分将被翻译。
命令结果输出到标准输出,如有需要可重定向到文件,或考虑使用 App::Greple::update 模块。
选项 --xlate 会调用 --xlate-color 选项并带有 --color=never 选项。
使用 --xlate-fold 选项时,转换后的文本会按指定宽度折行。默认宽度为 70,可通过 --xlate-fold-width 选项设置。为嵌入操作预留了四列,因此每行最多可容纳 74 个字符。
- --xlate-engine=engine
-
指定要使用的翻译引擎。如果直接指定引擎模块,如
-Mxlate::deepl,则无需使用此选项。目前可用的引擎如下
deepl: DeepL API
gpt3: gpt-3.5-turbo
gpt4: gpt-4.1
gpt4o: gpt-4o-mini
gpt-4o 的接口不稳定,目前无法保证正常工作。
- --xlate-labor
- --xlabor
-
不调用翻译引擎,而是由您手动操作。准备好要翻译的文本后,将其复制到剪贴板。您需要将其粘贴到表单中,复制结果到剪贴板,然后按回车键。
- --xlate-to (Default:
EN-US) -
指定目标语言。使用 DeepL 引擎时,可以通过
deepl languages命令获取可用语言。 - --xlate-format=format (Default:
conflict) -
指定原文和译文的输出格式。
除
xtxt外,以下格式假定要翻译的部分是多行集合。实际上,也可以只翻译一行的一部分,但指定除xtxt以外的格式不会产生有意义的结果。- conflict, cm
-
原文和转换后的文本以 git(1) 冲突标记格式输出。
<<<<<<< ORIGINAL original text ======= translated Japanese text >>>>>>> JA可以通过下一个 sed(1) 命令恢复原始文件。
sed -e '/^<<<<<<< /d' -e '/^=======$/,/^>>>>>>> /d' - colon, :::::::
-
原文和译文以 markdown 的自定义容器样式输出。
::::::: ORIGINAL original text ::::::: ::::::: JA translated Japanese text :::::::上述文本将被翻译为以下 HTML。
<div class="ORIGINAL"> original text </div> <div class="JA"> translated Japanese text </div>默认冒号数量为 7。如果指定类似
:::::的冒号序列,则会用该序列代替 7 个冒号。 - ifdef
-
原文和转换后的文本以 cpp(1)
#ifdef格式输出。#ifdef ORIGINAL original text #endif #ifdef JA translated Japanese text #endif您可以通过 unifdef 命令仅获取日文文本:
unifdef -UORIGINAL -DJA foo.ja.pm - space
- space+
-
原文和转换后的文本之间用一个空行分隔打印。
- xtxt
-
对于
space+,在转换后的文本后面也会输出一个换行符。
- --xlate-maxlen=chars (Default: 0)
-
如果格式为
xtxt(翻译后的文本)或未知,则只打印翻译后的文本。 - --xlate-maxline=n (Default: 0)
-
指定一次发送到 API 的最大文本长度。默认值设置为免费 DeepL 账户服务:API 为 128K(--xlate),剪贴板接口为 5000(--xlate-labor)。如果您使用的是 Pro 服务,可能可以更改这些值。
指定一次发送到 API 的最大文本行数。
- --[no-]xlate-progress (Default: True)
-
如果您希望一次只翻译一行,请将此值设置为 1。此选项优先于
--xlate-maxlen选项。 - --xlate-stripe
-
在 STDERR 输出中实时查看翻译结果。
使用 App::Greple::stripe 模块以斑马条纹方式显示匹配部分。当匹配部分首尾相连时,这很有用。
- --xlate-mask
-
颜色调色板会根据终端的背景色切换。如果您想明确指定,可以使用 --xlate-stripe-light 或 --xlate-stripe-dark。
- --match-all
-
执行掩码功能,并按原样显示转换后的文本而不进行还原。
- --lineify-cm
- --lineify-colon
-
对于
cm和colon格式,输出会被逐行拆分和格式化。因此,如果只翻译了一行的一部分,将无法获得预期的结果。这些过滤器可以修复因只翻译部分内容而导致输出损坏的问题,使其恢复为正常的逐行输出。在当前的实现中,如果一行的多个部分被翻译,它们会作为独立的行输出。
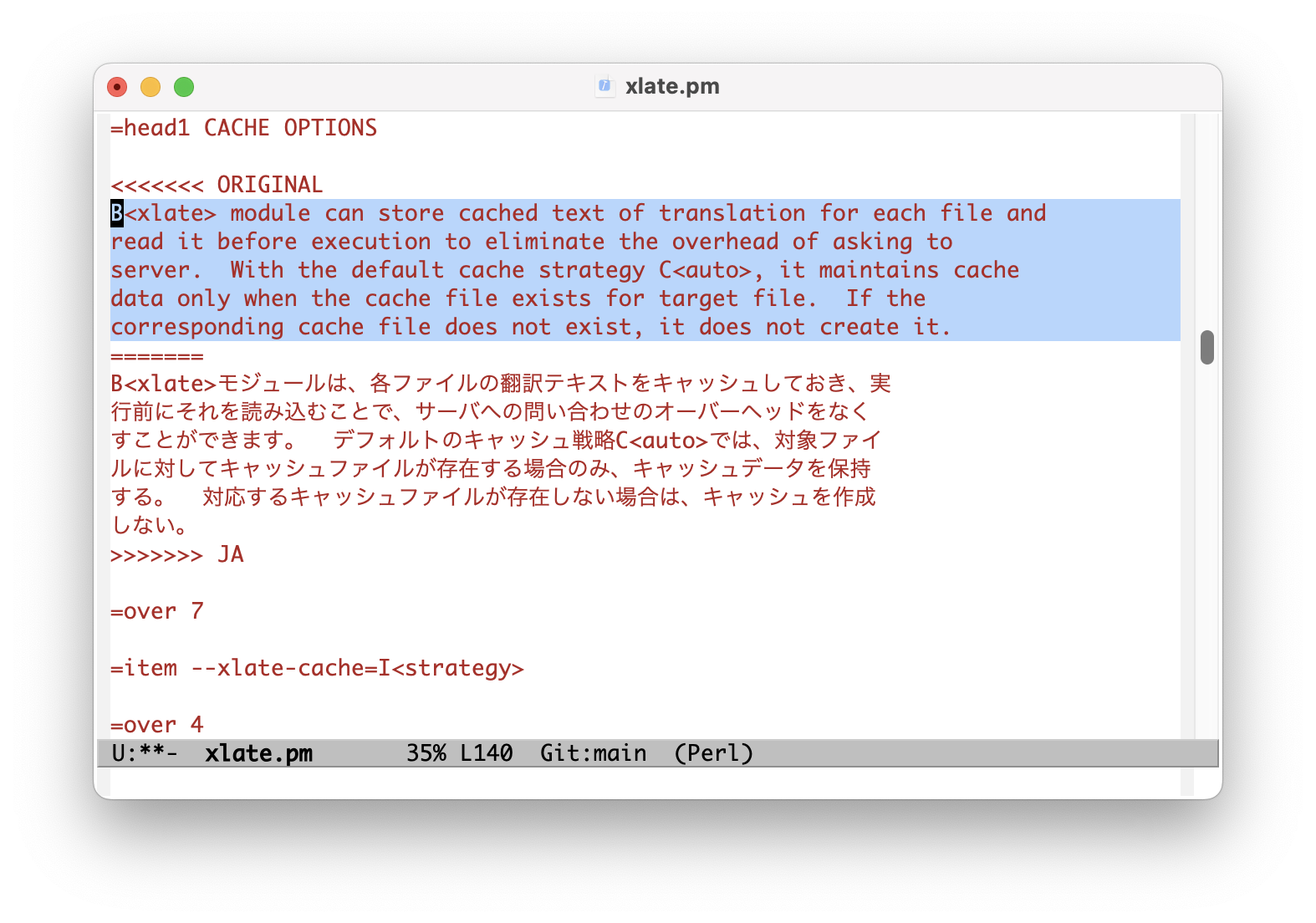
CACHE OPTIONS
将文件的全部文本设置为目标区域。
xlate 模块可以为每个文件存储翻译的缓存文本,并在执行前读取,以消除向服务器请求的开销。使用默认的缓存策略 auto,仅当目标文件存在缓存文件时才维护缓存数据。
COMMAND LINE INTERFACE
即使没有必要,此选项也会强制更新缓存文件。
您可以通过分发包中包含的 xlate 命令在命令行中轻松使用此模块。用法请参见 xlate man 页面。
xlate 命令可与 Docker 环境协同工作,因此即使您手头没有安装任何东西,只要有 Docker 可用,也可以使用。请使用 -D 或 -C 选项。
此外,由于提供了各种文档样式的 makefile,无需特殊指定即可翻译成其他语言。请使用 -M 选项。
您还可以结合 Docker 和 make 选项,在 Docker 环境中运行 make。
像 xlate -C 这样运行会启动一个挂载了当前工作 git 仓库的 shell。
EMACS
加载仓库中包含的 xlate.el 文件,以便在 Emacs 编辑器中使用 xlate 命令。xlate-region 函数用于翻译选定区域。默认语言为 EN-US,你可以通过前缀参数指定语言。
ENVIRONMENT
- DEEPL_AUTH_KEY
-
设置你的 DeepL 服务认证密钥。
- OPENAI_API_KEY
-
OpenAI 认证密钥。
INSTALL
CPANMINUS
$ cpanm App::Greple::xlateTOOLS
你需要为 DeepL 和 ChatGPT 安装命令行工具。
https://github.com/DeepLcom/deepl-python
https://github.com/tecolicom/App-gpty
SEE ALSO
https://hub.docker.com/r/tecolicom/xlate
Docker 容器镜像。
https://github.com/DeepLcom/deepl-python
DeepL Python 库和 CLI 命令。
https://github.com/openai/openai-python
OpenAI Python 库
https://github.com/tecolicom/App-gpty
OpenAI 命令行界面
-
有关目标文本模式的详细信息,请参见 greple 手册。使用 --inside、--outside、--include、--exclude 选项来限制匹配区域。
-
你可以使用
-Mupdate模块,根据 greple 命令的结果修改文件。 -
使用 sdif,结合 -V 选项,可以并排显示冲突标记格式。
-
Greple stripe 模块通过 --xlate-stripe 选项使用。
ARTICLES
https://qiita.com/kaz-utashiro/items/1c1a51a4591922e18250
Greple 模块仅用 DeepL API 翻译并替换必要部分(仅日文)
https://qiita.com/kaz-utashiro/items/a5e19736416ca183ecf6
使用 DeepL API 模块生成 15 种语言的文档(仅日文)
https://qiita.com/kaz-utashiro/items/1b9e155d6ae0620ab4dd
使用 DeepL API 的自动翻译 Docker 环境(仅日文)
AUTHOR
Kazumasa Utashiro
LICENSE
Copyright © 2023-2025 Kazumasa Utashiro.
This library is free software; you can redistribute it and/or modify it under the same terms as Perl itself.