NAME
MCE - Many-Core Engine for Perl providing parallel processing capabilities
VERSION
This document describes MCE version 1.799_02
Many-Core Engine (MCE) for Perl helps enable a new level of performance by maximizing all available cores.
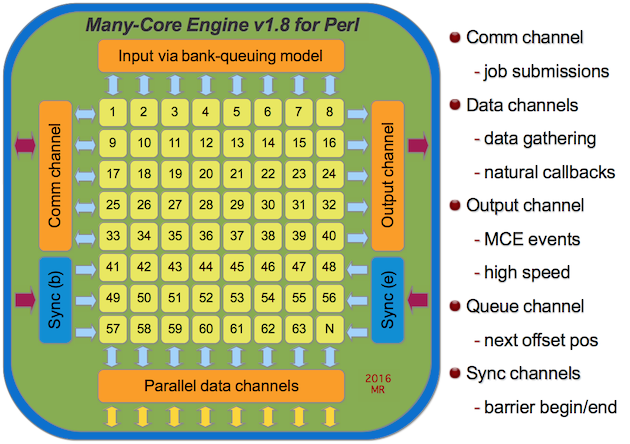
DESCRIPTION
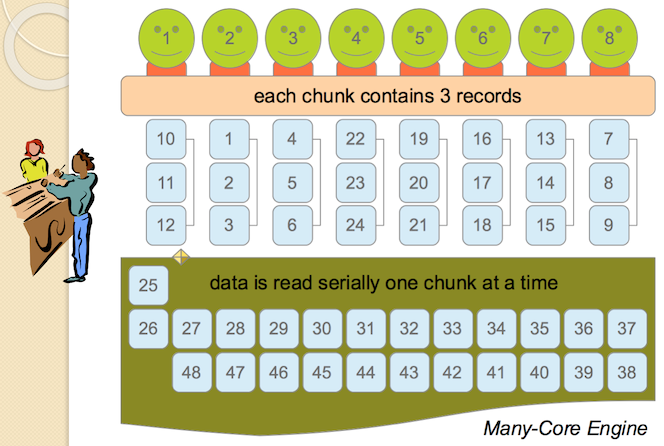
MCE spawns a pool of workers and therefore does not fork a new process per each element of data. Instead, MCE follows a bank queuing model. Imagine the line being the data and bank-tellers the parallel workers. MCE enhances that model by adding the ability to chunk the next n elements from the input stream to the next available worker.
SYNOPSIS
This is a simplistic use case of MCE running with 5 workers.
# Construction using the Core API
use MCE;
my $mce = MCE->new(
max_workers => 5,
user_func => sub {
my ($mce) = @_;
$mce->say("Hello from " . $mce->wid);
}
);
$mce->run;
# Construction using a MCE model
use MCE::Flow max_workers => 5;
mce_flow sub {
my ($mce) = @_;
MCE->say("Hello from " . MCE->wid);
};The following is a demonstration for parsing a huge log file in parallel.
use MCE::Loop;
MCE::Loop::init { max_workers => 8, use_slurpio => 1 };
my $pattern = 'something';
my $hugefile = 'very_huge.file';
my @result = mce_loop_f {
my ($mce, $slurp_ref, $chunk_id) = @_;
# Quickly determine if a match is found.
# Process the slurped chunk only if true.
if ($$slurp_ref =~ /$pattern/m) {
my @matches;
# The following is fast on Unix, but performance degrades
# drastically on Windows beyond 4 workers.
open my $MEM_FH, '<', $slurp_ref;
binmode $MEM_FH, ':raw';
while (<$MEM_FH>) { push @matches, $_ if (/$pattern/); }
close $MEM_FH;
# Therefore, use the following construction on Windows.
while ( $$slurp_ref =~ /([^\n]+\n)/mg ) {
my $line = $1; # save $1 to not lose the value
push @matches, $line if ($line =~ /$pattern/);
}
# Gather matched lines.
MCE->gather(@matches);
}
} $hugefile;
print join('', @result);The next demonstration loops through a sequence of numbers with MCE::Flow.
use MCE::Flow;
my $N = shift || 4_000_000;
sub compute_pi {
my ( $beg_seq, $end_seq ) = @_;
my ( $pi, $t ) = ( 0.0 );
foreach my $i ( $beg_seq .. $end_seq ) {
$t = ( $i + 0.5 ) / $N;
$pi += 4.0 / ( 1.0 + $t * $t );
}
MCE->gather( $pi );
}
# Compute bounds only, workers receive [ begin, end ] values
MCE::Flow::init(
chunk_size => 200_000,
max_workers => 8,
bounds_only => 1
);
my @ret = mce_flow_s sub {
compute_pi( $_->[0], $_->[1] );
}, 0, $N - 1;
my $pi = 0.0; $pi += $_ for @ret;
printf "pi = %0.13f\n", $pi / $N; # 3.1415926535898CORE MODULES
Three modules make up the core engine for MCE.
- MCE::Core
-
Provides the Core API for Many-Core Engine. The various MCE options are described here.
- MCE::Signal
-
Temporary directory creation, cleanup, and signal handling.
- MCE::Util
-
Utility functions for Many-Core Engine.
MCE EXTRAS
There are 4 add-on modules for use with MCE.
- MCE::Candy
-
Provides a collection of sugar methods and output iterators for preserving output order.
- MCE::Mutex
-
Provides a simple semaphore implementation supporting threads and processes.
- MCE::Queue
-
Provides a hybrid queuing implementation for MCE supporting normal queues and priority queues from a single module. MCE::Queue exchanges data via the core engine to enable queuing to work for both children (spawned from fork) and threads.
- MCE::Relay
-
Enables workers to receive and pass on information orderly with zero involvement by the manager process while running.
MCE MODELS
The models take Many-Core Engine to a new level for ease of use. Two options (chunk_size and max_workers) are configured automatically as well as spawning and shutdown.
- MCE::Loop
-
Provides a parallel loop utilizing MCE for building creative loops.
- MCE::Flow
-
A parallel flow model for building creative applications. This makes use of user_tasks in MCE. The author has full control when utilizing this model. MCE::Flow is similar to MCE::Loop, but allows for multiple code blocks to run in parallel with a slight change to syntax.
- MCE::Grep
-
Provides a parallel grep implementation similar to the native grep function.
- MCE::Map
-
Provides a parallel map model similar to the native map function.
- MCE::Step
-
Provides a parallel step implementation utilizing MCE::Queue between user tasks. MCE::Step is a spin off from MCE::Flow with a touch of MCE::Stream. This model, introduced in 1.506, allows one to pass data from one sub-task into the next transparently.
- MCE::Stream
-
Provides an efficient parallel implementation for chaining multiple maps and greps together through user_tasks and MCE::Queue. Like with MCE::Flow, MCE::Stream can run multiple code blocks in parallel with a slight change to syntax from MCE::Map and MCE::Grep.
MISCELLANEOUS
Miscellaneous additions included with the distribution.
- MCE::Examples
-
Describes various demonstrations for MCE including a Monte Carlo simulation.
- MCE::Subs
-
Exports functions mapped directly to MCE methods; e.g. mce_wid. The module allows 3 options; :manager, :worker, and :getter.
REQUIREMENTS
Perl 5.8.0 or later. PDL::IO::Storable is required in scripts running PDL.
SOURCE AND FURTHER READING
The source, cookbook, and examples are hosted at GitHub.
SEE ALSO
MCE::Shared provides data sharing capabilities for MCE. It includes MCE::Hobo for running code asynchronously.
AUTHOR
Mario E. Roy, <marioeroy AT gmail DOT com>
COPYRIGHT AND LICENSE
Copyright (C) 2012-2016 by Mario E. Roy
MCE is released under the same license as Perl.
See http://dev.perl.org/licenses/ for more information.