NAME
App::Greple::xlate - greple的翻译支持模块
SYNOPSIS
greple -Mxlate -e ENGINE --xlate pattern target-file
greple -Mxlate::deepl --xlate pattern target-fileVERSION
Version 0.3401
DESCRIPTION
Greple xlate 模块查找所需的文本块,并用翻译文本替换它们。目前,DeepL (deepl.pm) 和 ChatGPT (gpt3.pm) 模块被用作后端引擎。此外,还包括对 gpt-4 和 gpt-4o 的实验性支持。
如果要翻译以 Perl 的 pod 风格编写的文档中的普通文本块,请使用 greple 命令,并像这样使用 xlate::deepl 和 perl 模块:
greple -Mxlate::deepl -Mperl --pod --re '^(\w.*\n)+' --all foo.pm在该命令中,模式字符串 ^(\w.*\n)+ 表示以字母数字开头的连续行。该命令高亮显示要翻译的区域。选项 --all 用于生成整个文本。
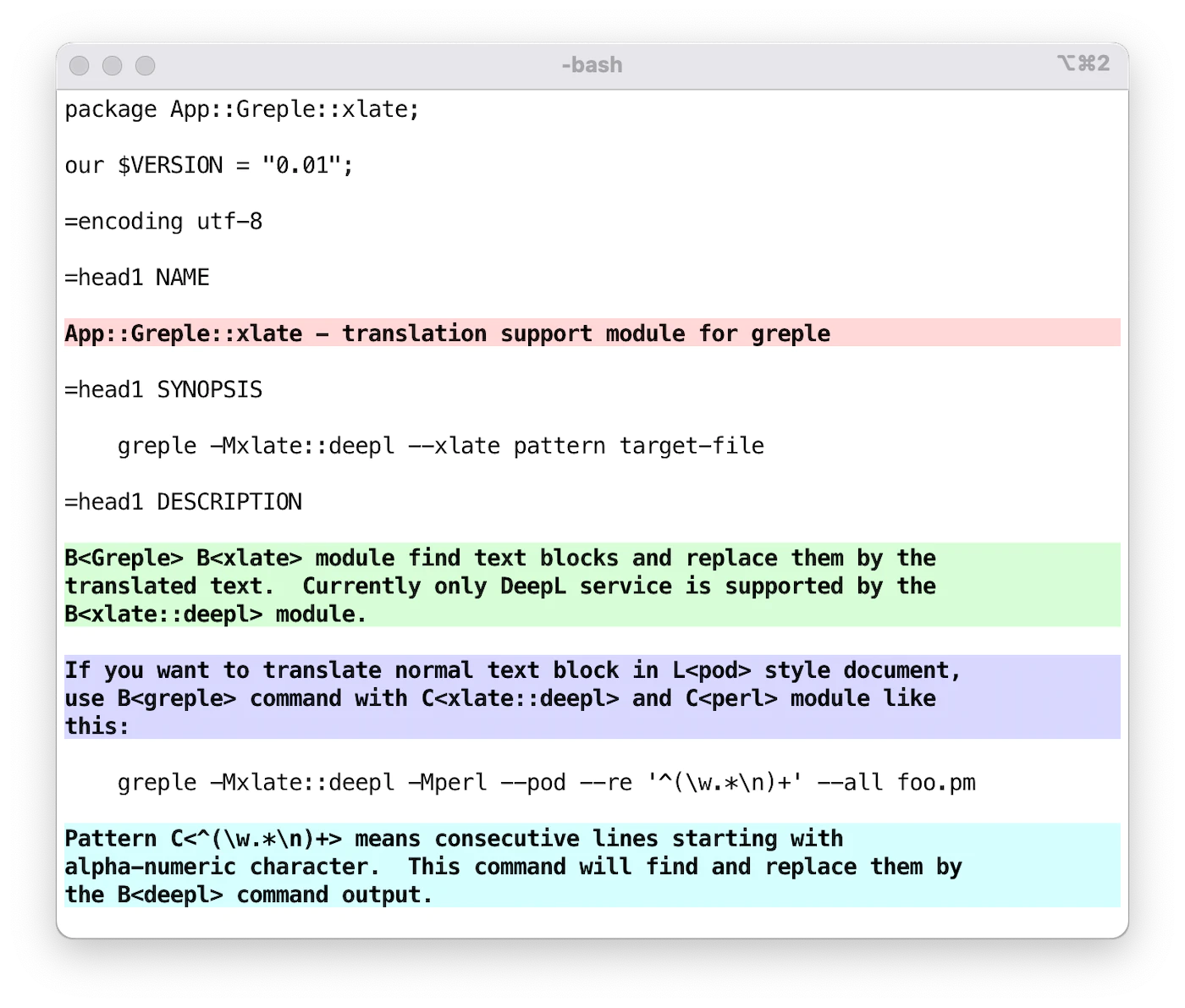
然后添加 --xlate 选项来翻译选定区域。然后,它会找到所需的部分,并用 deepl 命令输出将其替换。
默认情况下,原文和译文以与 git(1) 兼容的 "冲突标记 "格式打印。使用 ifdef 格式,可以通过 unifdef(1) 命令轻松获得所需的部分。输出格式可以通过 --xlate-format 选项指定。
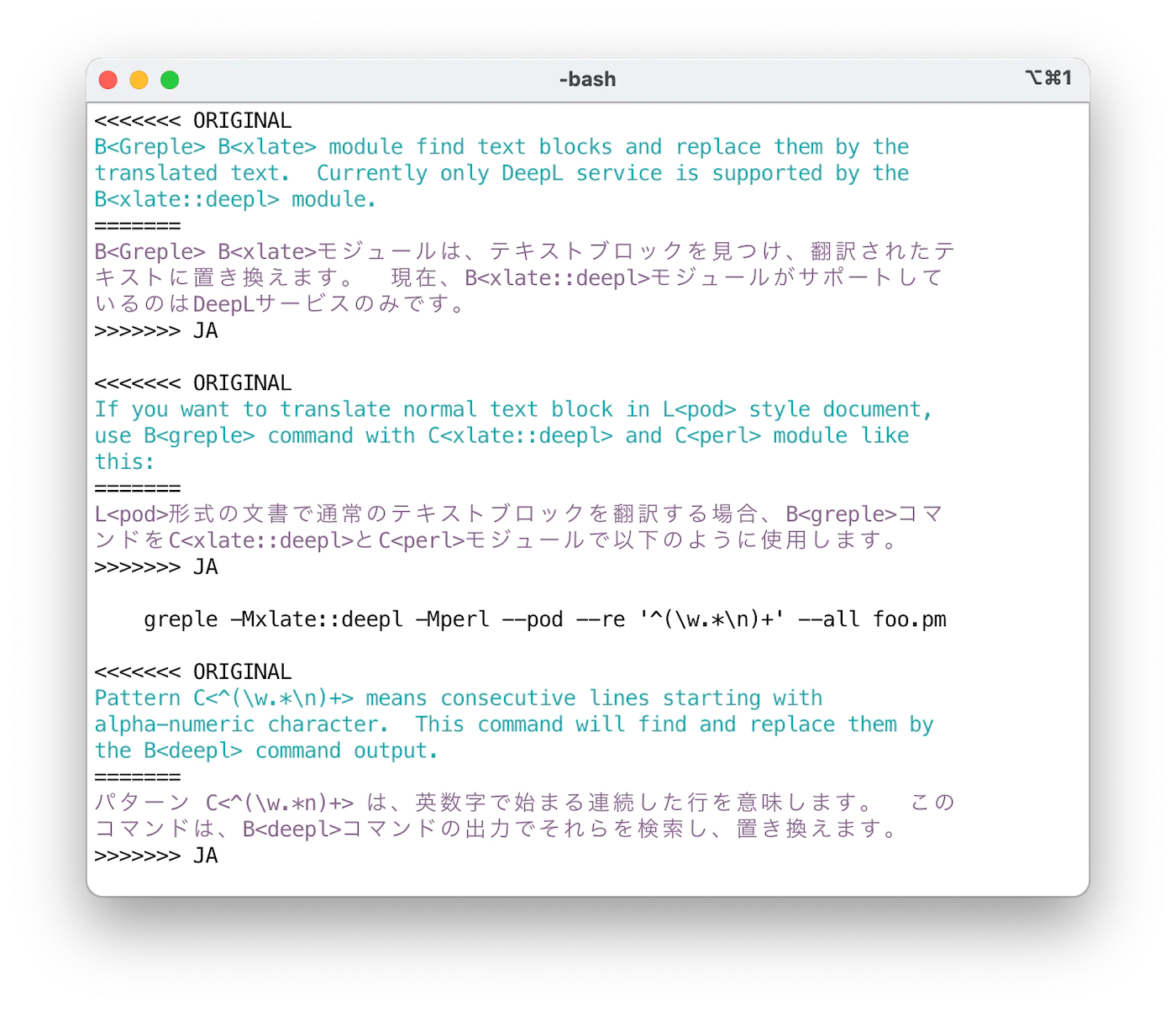
如果要翻译整个文本,请使用 --match-all 选项。这是指定匹配整个文本的模式 (?s).+ 的快捷方式。
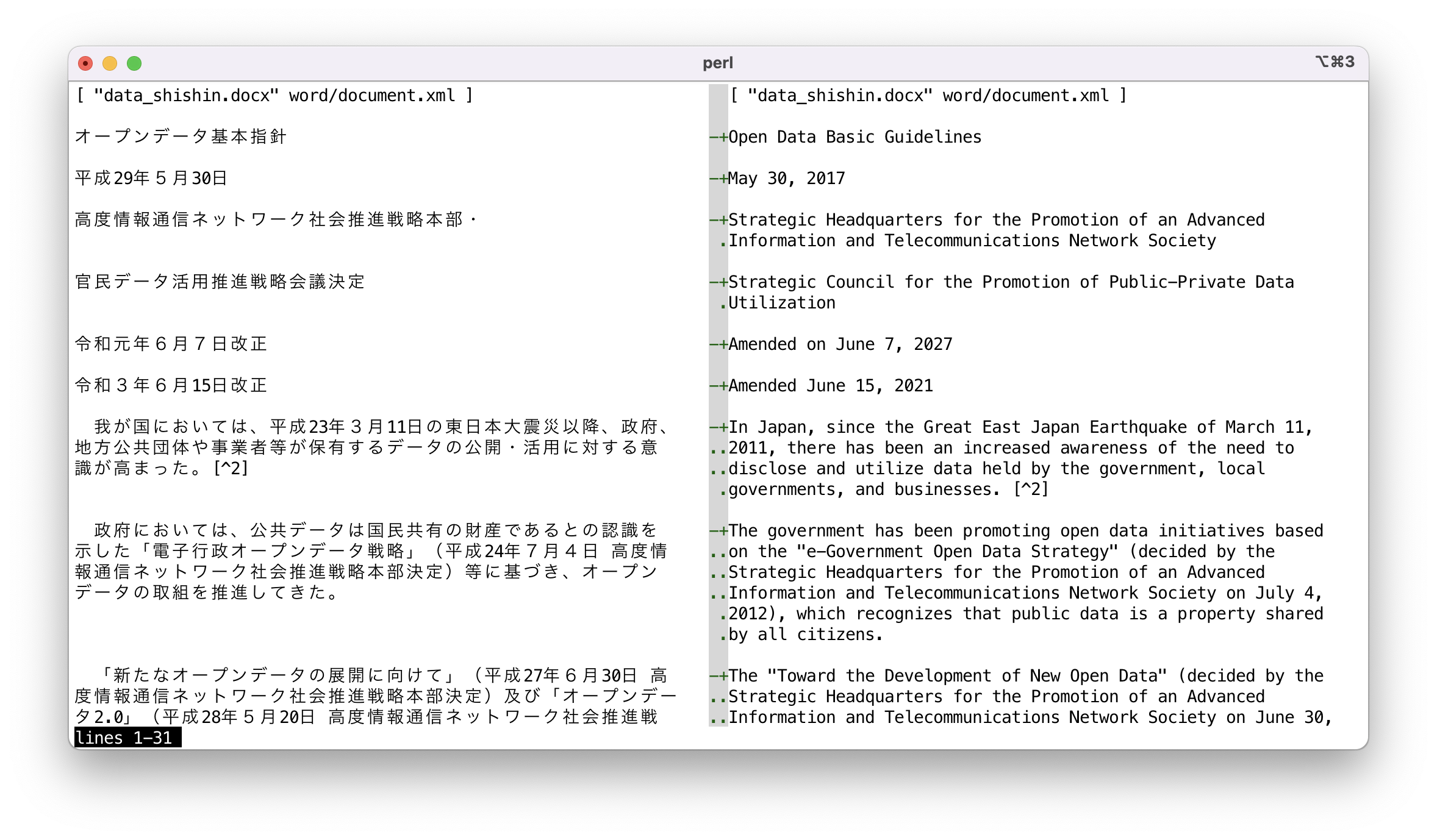
冲突标记格式数据可以通过带有 -V 选项的 sdif 命令并排查看。由于按字符串进行比较毫无意义,因此建议使用 --no-cdif 选项。如果不需要给文本着色,可指定 --no-textcolor(或 --no-tc)。
sdif -V --no-tc --no-cdif data_shishin.deepl-EN-US.cm
NORMALIZATION
处理是以指定单位进行的,但如果是多行非空文本序列,则会一起转换为单行。具体操作如下
删除每行开头和结尾的空白。
如果一行以全角标点符号结束,则与下一行连接。
如果一行以全角字符结束,而下一行以全角字符开始,则将这两行连接起来。
如果一行的末尾或开头不是全宽字符,则通过插入空格字符将它们连接起来。
缓存数据是根据规范化文本进行管理的,因此即使进行了不影响规范化结果的修改,缓存的翻译数据仍然有效。
此规范化处理只针对第一个(第 0 个)和偶数模式。因此,如果指定了以下两个模式,则匹配第一个模式的文本将在规范化后处理,而不对匹配第二个模式的文本执行规范化处理。
greple -Mxlate -E normalized -E not-normalized因此,对于要将多行合并为一行进行处理的文本,请使用第一个模式,而对于预格式化文本,请使用第二个模式。如果第一种模式中没有要匹配的文本,那么就使用不匹配任何内容的模式,如 (?!)。
MASKING
有时,您不希望翻译文本中的某些部分。例如,markdown 文件中的标记。DeepL 建议在这种情况下,将不需要翻译的文本部分转换为 XML 标记,然后进行翻译,翻译完成后再还原。为了支持这一点,可以指定要屏蔽翻译的部分。
--xlate-setopt maskfile=MASKPATTERN这将把文件 `MASKPATTERN` 的每一行都解释为正则表达式,翻译与之匹配的字符串,并在处理后还原。以 # 开头的行将被忽略。
此接口为试验性接口,将来可能会更改。
OPTIONS
- --xlate
- --xlate-color
- --xlate-fold
- --xlate-fold-width=n (Default: 70)
-
对每个匹配的区域调用翻译过程。
如果没有这个选项,greple的行为就像一个普通的搜索命令。所以你可以在调用实际工作之前检查文件的哪一部分将成为翻译的对象。
命令的结果会进入标准输出,所以如果需要的话,可以重定向到文件,或者考虑使用App::Greple::update模块。
选项--xlate调用--xlate-color选项与--color=never选项。
使用--xlate-fold选项,转换后的文本将按指定的宽度进行折叠。默认宽度为70,可以通过--xlate-fold-width选项设置。四列是为磨合操作保留的,所以每行最多可以容纳74个字符。
- --xlate-engine=engine
-
指定要使用的翻译引擎。如果直接指定引擎模块,如
-Mxlate::deepl,则无需使用此选项。目前有以下引擎
deepl: DeepL API
gpt3: gpt-3.5-turbo
gpt4: gpt-4-turbo
gpt4o: gpt-4o-mini
gpt-4o 的接口不稳定,目前无法保证正常工作。
- --xlate-labor
- --xlabor
-
您需要做的不是调用翻译引擎,而是为其工作。准备好要翻译的文本后,它们会被复制到剪贴板。您需要将它们粘贴到表单中,将结果复制到剪贴板,然后点击回车键。
- --xlate-to (Default:
EN-US) -
指定目标语言。当使用DeepL引擎时,你可以通过
deepl languages命令获得可用语言。 - --xlate-format=format (Default:
conflict) -
指定原始和翻译文本的输出格式。
除
xtxt以外的下列格式假定要翻译的部分是行的集合。事实上,有可能只翻译一行的一部分,因此指定xtxt以外的格式不会产生有意义的结果。- conflict, cm
-
原始文本和转换后的文本以 git(1) 冲突标记格式打印。
<<<<<<< ORIGINAL original text ======= translated Japanese text >>>>>>> JA你可以通过下一个sed(1)命令恢复原始文件。
sed -e '/^<<<<<<< /d' -e '/^=======$/,/^>>>>>>> /d' - ifdef
-
原始文本和转换后的文本以 cpp(1)
#ifdef格式打印。#ifdef ORIGINAL original text #endif #ifdef JA translated Japanese text #endif你可以通过unifdef命令只检索日文文本。
unifdef -UORIGINAL -DJA foo.ja.pm - space
-
原始文本和转换后的文本以单行空行分隔打印。
- xtxt
-
如果格式是
xtxt(翻译文本)或不知道,则只打印翻译文本。
- --xlate-maxlen=chars (Default: 0)
-
指定一次发送到 API 的最大文本长度。默认值与 DeepL 免费账户服务一样:API (--xlate) 为 128K,剪贴板界面 (--xlate-labor) 为 5000。如果使用专业版服务,您可以更改这些值。
- --xlate-maxline=n (Default: 0)
-
指定一次发送到 API 的最大文本行数。
如果想一次翻译一行,则将该值设为 1。该选项优先于
--xlate-maxlen选项。 - --[no-]xlate-progress (Default: True)
-
在STDERR输出中可以看到实时的翻译结果。
- --match-all
-
将文件的整个文本设置为目标区域。
CACHE OPTIONS
xlate模块可以存储每个文件的翻译缓存文本,并在执行前读取它,以消除向服务器请求的开销。在默认的缓存策略auto下,它只在目标文件的缓存文件存在时才维护缓存数据。
- --cache-clear
-
--cache-clear选项可以用来启动缓冲区管理或刷新所有现有的缓冲区数据。一旦用这个选项执行,如果不存在一个新的缓存文件,就会创建一个新的缓存文件,然后自动维护。
- --xlate-cache=strategy
COMMAND LINE INTERFACE
通过使用发行版中的 xlate 命令,您可以轻松地从命令行使用该模块。有关用法,请参阅 xlate 帮助信息。
xlate 命令与 Docker 环境协同工作,因此即使你手头没有安装任何东西,只要 Docker 可用,你就可以使用它。使用 -D 或 -C 选项。
此外,由于提供了各种文档样式的 makefile,因此无需特别说明即可翻译成其他语言。使用 -M 选项。
你还可以将 Docker 和 make 选项结合起来,以便在 Docker 环境中运行 make。
像 xlate -GC 这样运行,会启动一个挂载了当前工作 git 仓库的 shell。
详情请阅读 "SEE ALSO" 部分的日文文章。
xlate [ options ] -t lang file [ greple options ]
-h help
-v show version
-d debug
-n dry-run
-a use API
-c just check translation area
-r refresh cache
-s silent mode
-e # translation engine (default "deepl")
-p # pattern to determine translation area
-w # wrap line by # width
-o # output format (default "xtxt", or "cm", "ifdef")
-f # from lang (ignored)
-t # to lang (required, no default)
-m # max length per API call
-l # show library files (XLATE.mk, xlate.el)
-- terminate option parsing
Make options
-M run make
-n dry-run
Docker options
-G mount git top-level directory
-B run in non-interactive (batch) mode
-R mount read-only
-E * specify environment variable to be inherited
-I * specify altanative docker image (default: tecolicom/xlate:version)
-D * run xlate on the container with the rest parameters
-C * run following command on the container, or run shell
Control Files:
*.LANG translation languates
*.FORMAT translation foramt (xtxt, cm, ifdef)
*.ENGINE translation engine (deepl or gpt3)EMACS
加载存储库中的xlate.el文件,从Emacs编辑器中使用xlate命令。xlate-region函数翻译给定的区域。默认的语言是EN-US,你可以用前缀参数指定调用语言。
ENVIRONMENT
- DEEPL_AUTH_KEY
-
为DeepL 服务设置你的认证密钥。
- OPENAI_API_KEY
-
OpenAI 验证密钥。
INSTALL
CPANMINUS
$ cpanm App::Greple::xlateTOOLS
您必须安装 DeepL 和 ChatGPT 的命令行工具。
https://github.com/DeepLcom/deepl-python
https://github.com/tecolicom/App-gpty
SEE ALSO
https://hub.docker.com/r/tecolicom/xlate
- https://github.com/DeepLcom/deepl-python
-
DeepL Python库和CLI命令。
- https://github.com/openai/openai-python
-
OpenAI Python 库
- https://github.com/tecolicom/App-gpty
-
OpenAI 命令行界面
- App::Greple
-
关于目标文本模式的细节,请参见greple手册。使用--inside, --outside, --include, --exclude选项来限制匹配区域。
- App::Greple::update
-
你可以使用
-Mupdate模块通过greple命令的结果来修改文件。 - App::sdif
-
使用sdif与-V选项并列显示冲突标记格式。
ARTICLES
https://qiita.com/kaz-utashiro/items/1c1a51a4591922e18250
使用 DeepL API(日语)翻译并仅替换必要部分的 Greple 模块
https://qiita.com/kaz-utashiro/items/a5e19736416ca183ecf6
利用 DeepL API 模块生成 15 种语言的文档(日语)
https://qiita.com/kaz-utashiro/items/1b9e155d6ae0620ab4dd
利用 DeepL API 自动翻译 Docker 环境(日语)
AUTHOR
Kazumasa Utashiro
LICENSE
Copyright © 2023-2024 Kazumasa Utashiro.
This library is free software; you can redistribute it and/or modify it under the same terms as Perl itself.