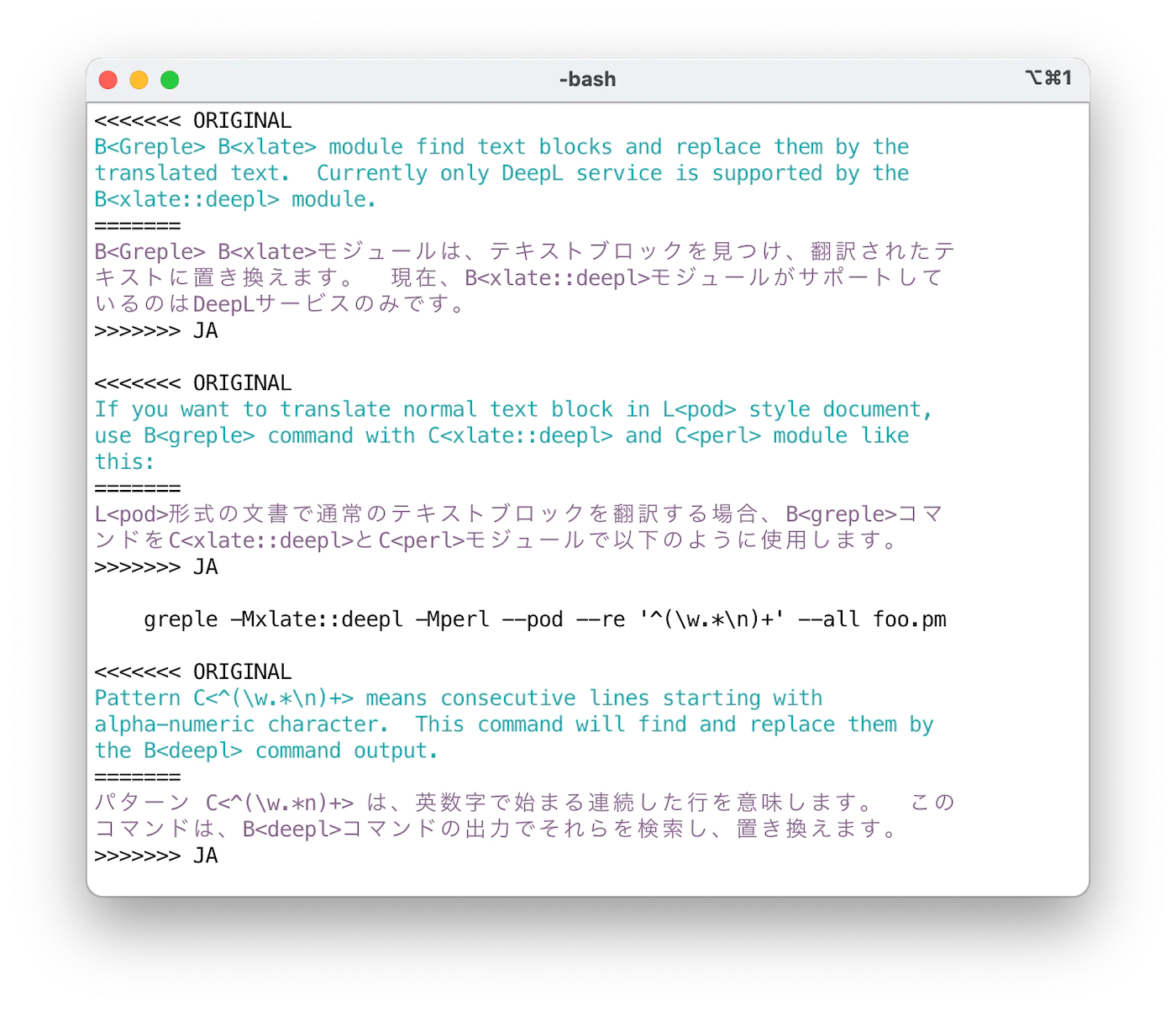
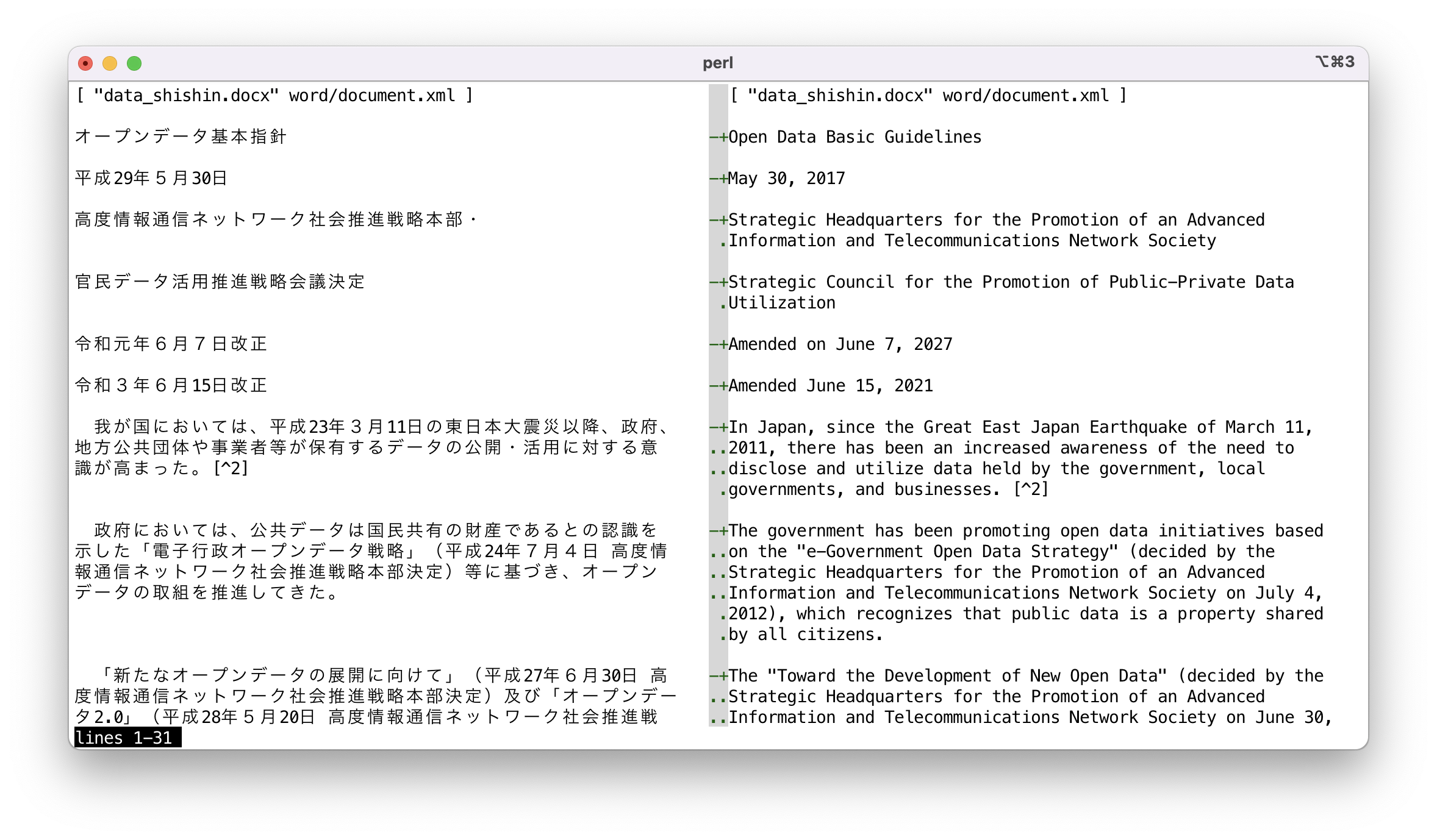
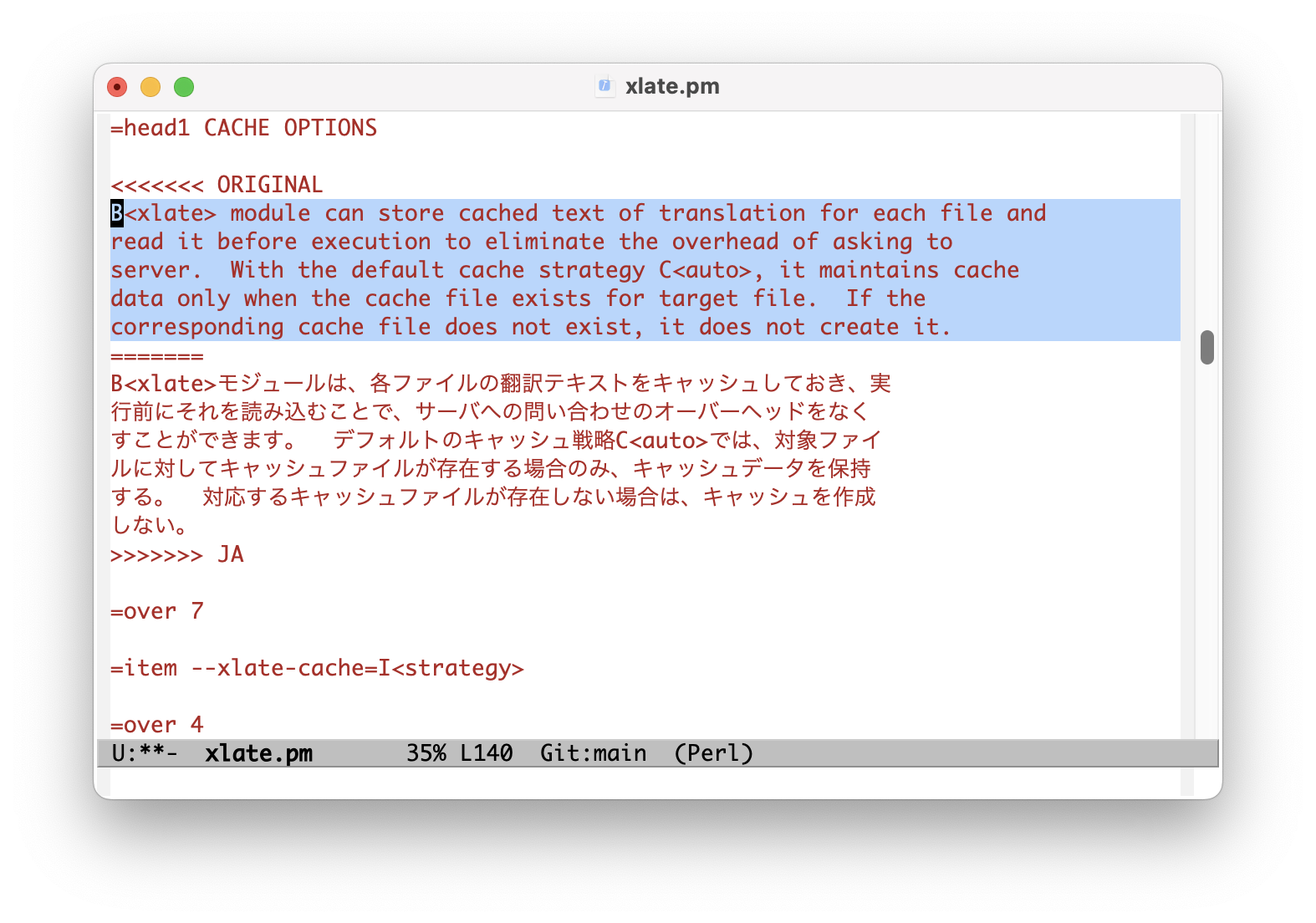
=encoding utf-8=head1 NAMEApp::Greple::xlate - module de support de traduction pour greple=head1 SYNOPSISgreple -Mxlate -e ENGINE --xlate pattern target-filegreple -Mxlate::deepl --xlate pattern target-file=head1 VERSIONVersion 0.9908=head1 DESCRIPTIONLe module B<Greple> B<xlate> trouve les blocs de texte souhaités et les remplace par le texte traduit. Actuellement, les modules DeepL (F<deepl.pm>) et ChatGPT (F<gpt3.pm>) sont implémentés en tant que moteur en arrière-plan. Un support expérimental pour gpt-4 et gpt-4o est également inclus.Si vous souhaitez traduire des blocs de texte normaux dans un document écrit dans le style pod de Perl, utilisez la commande B<greple> avec les modules C<xlate::deepl> et C<perl> de cette manière :greple -Mxlate::deepl -Mperl --pod --re '^([\w\pP].*\n)+' --all foo.pmDans cette commande, la chaîne de motif C<^([\w\pP].*\n)+> signifie des lignes consécutives commençant par une lettre alphanumérique et de ponctuation. Cette commande affiche la zone à traduire mise en évidence. L'option B<--all> est utilisée pour produire l'intégralité du texte.=for html <p><img width="750" src="https://raw.githubusercontent.com/kaz-utashiro/App-Greple-xlate/main/images/select-area.png"></p>Ensuite, ajoutez l'option C<--xlate> pour traduire la zone sélectionnée. Ensuite, il trouvera les sections souhaitées et les remplacera par la sortie de la commande B<deepl>.Par défaut, le texte original et traduit est affiché dans le format "conflict marker" compatible avec L<git(1)>. En utilisant le format C<ifdef>, vous pouvez obtenir la partie souhaitée avec la commande L<unifdef(1)> facilement. Le format de sortie peut être spécifié avec l'option B<--xlate-format>.=for html <p><img width="750" src="https://raw.githubusercontent.com/kaz-utashiro/App-Greple-xlate/main/images/format-conflict.png"></p>Si vous souhaitez traduire l'intégralité du texte, utilisez l'option B<--match-all>. Il s'agit d'un raccourci pour spécifier le motif C<(?s).+> qui correspond à l'ensemble du texte.Le format des données de marqueur de conflit peut être visualisé en style côte à côte en utilisant la commande C<sdif> avec l'option C<-V>. Comme il n'a pas de sens de comparer sur une base par chaîne, l'option C<--no-cdif> est recommandée. Si vous n'avez pas besoin de colorer le texte, spécifiez C<--no-textcolor> (ou C<--no-tc>).sdif -V --no-tc --no-cdif data_shishin.deepl-EN-US.cm=for html <p><img width="750" src="https://raw.githubusercontent.com/kaz-utashiro/App-Greple-xlate/main/images/sdif-cm-view.png"></p>=head1 NORMALIZATIONLe traitement est effectué en unités spécifiées, mais dans le cas d'une séquence de plusieurs lignes de texte non vide, elles sont converties ensemble en une seule ligne. Cette opération est effectuée comme suit :=over 2=item *Supprimer les espaces blancs au début et à la fin de chaque ligne.=item *Si une ligne se termine par un caractère de ponctuation en pleine largeur, concaténez avec la ligne suivante.=item *Si une ligne se termine par un caractère pleine largeur et que la ligne suivante commence par un caractère pleine largeur, concaténer les lignes.=item *Si la fin ou le début d'une ligne n'est pas un caractère pleine largeur, les concaténer en insérant un caractère d'espace.=backLes données du cache sont gérées en fonction du texte normalisé, donc même si des modifications sont apportées qui n'affectent pas les résultats de normalisation, les données de traduction mises en cache resteront efficaces.Ce processus de normalisation est effectué uniquement pour le premier (0e) et le motif de numéro pair. Ainsi, si deux motifs sont spécifiés comme suit, le texte correspondant au premier motif sera traité après la normalisation, et aucun processus de normalisation ne sera effectué sur le texte correspondant au deuxième motif.greple -Mxlate -E normalized -E not-normalizedPar conséquent, utilisez le premier modèle pour le texte qui doit être traité en combinant plusieurs lignes en une seule ligne, et utilisez le deuxième modèle pour le texte préformaté. S'il n'y a pas de texte à correspondre dans le premier modèle, utilisez un modèle qui ne correspond à rien, comme C<(?!)>.=head1 MASKINGDe temps en temps, il y a des parties de texte que vous ne voulez pas traduire. Par exemple, les balises dans les fichiers markdown. DeepL suggère que dans de tels cas, la partie du texte à exclure soit convertie en balises XML, traduite, puis restaurée une fois la traduction terminée. Pour prendre en charge cela, il est possible de spécifier les parties à masquer de la traduction.--xlate-setopt maskfile=MASKPATTERNCela interprétera chaque ligne du fichier `MASKPATTERN` comme une expression régulière, traduira les chaînes qui lui correspondent, puis les rétablira après le traitement. Les lignes commençant par C<#> sont ignorées.Un motif complexe peut être écrit sur plusieurs lignes avec un retour à la ligne échappé par un backslash.Comment le texte est transformé par le masquage peut être vu en utilisant l'option B<--xlate-mask>.Cette interface est expérimentale et sujette à modification à l'avenir.=head1 OPTIONS=over 7=item B<--xlate>=item B<--xlate-color>=item B<--xlate-fold>=item B<--xlate-fold-width>=I<n> (Default: 70)Lancez le processus de traduction pour chaque zone correspondante.Sans cette option, B<greple> se comporte comme une commande de recherche normale. Vous pouvez donc vérifier quelle partie du fichier sera soumise à la traduction avant de lancer le travail réel.Le résultat de la commande est renvoyé sur la sortie standard, donc redirigez-le vers un fichier si nécessaire, ou envisagez d'utiliser le module L<App::Greple::update>.L'option B<--xlate> appelle l'option B<--xlate-color> avec l'option B<--color=never>.Avec l'option B<--xlate-fold>, le texte converti est plié selon la largeur spécifiée. La largeur par défaut est de 70 et peut être définie par l'option B<--xlate-fold-width>. Quatre colonnes sont réservées pour l'opération run-in, donc chaque ligne peut contenir au maximum 74 caractères.=item B<--xlate-engine>=I<engine>Spécifie le moteur de traduction à utiliser. Si vous spécifiez directement le module du moteur, tel que C<-Mxlate::deepl>, vous n'avez pas besoin d'utiliser cette option.À l'heure actuelle, les moteurs suivants sont disponibles=over 2=item * B<deepl>: DeepL API=item * B<gpt3>: gpt-3.5-turbo=item * B<gpt4>: gpt-4-turbo=item * B<gpt4o>: gpt-4o-miniL'interface de B<gpt-4o> est instable et ne peut pas être garantie de fonctionner correctement pour le moment.=back=item B<--xlate-labor>=item B<--xlabor>Au lieu d'appeler le moteur de traduction, vous êtes censé travailler pour lui. Après avoir préparé le texte à traduire, il est copié dans le presse-papiers. Vous êtes censé le coller dans le formulaire, copier le résultat dans le presse-papiers et appuyer sur Entrée.=item B<--xlate-to> (Default: C<EN-US>)Spécifiez la langue cible. Vous pouvez obtenir les langues disponibles avec la commande C<deepl languages> lorsque vous utilisez le moteur B<DeepL>.=item B<--xlate-format>=I<format> (Default: C<conflict>)Spécifiez le format de sortie pour le texte original et traduit.Les formats suivants autres que C<xtxt> supposent que la partie à traduire est une collection de lignes. En fait, il est possible de traduire seulement une partie d'une ligne, et spécifier un format autre que C<xtxt> ne produira pas de résultats significatifs.=over 4=item B<conflict>, B<cm>Original et texte converti sont imprimés au format de marqueur de conflit L<git(1)>.<<<<<<< ORIGINALoriginal text=======translated Japanese text>>>>>>> JAVous pouvez récupérer le fichier original avec la commande L<sed(1)> suivante.sed -e '/^<<<<<<< /d' -e '/^=======$/,/^>>>>>>> /d'=item B<colon>, I<:::::::>```html::::::: ORIGINALoriginal text:::::::::::::: JAtranslated Japanese text:::::::<div style="background-color: #f4f4f4; color: #333; border-left: 6px solid #3c763d; padding: 10px; margin-bottom: 10px;"><div class="ORIGINAL">original text</div><div class="JA">translated Japanese text</div>Le nombre de deux-points est de 7 par défaut. Si vous spécifiez une séquence de deux-points comme C<:::::>, elle est utilisée à la place de 7 deux-points.=item B<ifdef>Original et texte converti sont imprimés au format C<#ifdef> L<cpp(1)>.#ifdef ORIGINALoriginal text#endif#ifdef JAtranslated Japanese text#endifVous pouvez récupérer uniquement le texte japonais avec la commande B<unifdef> :unifdef -UORIGINAL -DJA foo.ja.pm=item B<space>=item B<space+>Original text:=item B<xtxt>Si le format est C<xtxt> (texte traduit) ou inconnu, seul le texte traduit est imprimé.=back=item B<--xlate-maxlen>=I<chars> (Default: 0)Traduisez le texte suivant en français, ligne par ligne.=item B<--xlate-maxline>=I<n> (Default: 0)Spécifiez le nombre maximum de lignes de texte à envoyer à l'API à la fois.Définissez cette valeur sur 1 si vous souhaitez traduire une ligne à la fois. Cette option a la priorité sur l'option C<--xlate-maxlen>.=item B<-->[B<no->]B<xlate-progress> (Default: True)Voyez le résultat de la traduction en temps réel dans la sortie STDERR.=item B<--xlate-stripe>Utilisez le module L<App::Greple::stripe> pour afficher la partie correspondante de manière zébrée. Cela est utile lorsque les parties correspondantes sont connectées dos à dos.La palette de couleurs est basculée en fonction de la couleur de fond du terminal. Si vous souhaitez spécifier explicitement, vous pouvez utiliser B<--xlate-stripe-light> ou B<--xlate-stripe-dark>.=item B<--xlate-mask>Effectuez la fonction de masquage et affichez le texte converti tel quel sans restauration.=item B<--match-all>Définissez l'intégralité du texte du fichier comme zone cible.=back=head1 CACHE OPTIONSLe module B<xlate> peut stocker le texte traduit en cache pour chaque fichier et le lire avant l'exécution pour éliminer les frais généraux de demande au serveur. Avec la stratégie de cache par défaut C<auto>, il ne conserve les données en cache que lorsque le fichier de cache existe pour le fichier cible.Utilisez B<--xlate-cache=clear> pour initier la gestion du cache ou pour nettoyer toutes les données de cache existantes. Une fois exécutée avec cette option, un nouveau fichier de cache sera créé s'il n'existe pas, puis automatiquement maintenu par la suite.=over 7=item --xlate-cache=I<strategy>=over 4=item C<auto> (Default)Maintenez le fichier de cache s'il existe.=item C<create>Créez un fichier de cache vide et quittez.=item C<always>, C<yes>, C<1>Maintenez le cache de toute façon tant que la cible est un fichier normal.=item C<clear>Effacez d'abord les données du cache.=item C<never>, C<no>, C<0>N'utilisez jamais le fichier de cache même s'il existe.=item C<accumulate>Par défaut, les données inutilisées sont supprimées du fichier de cache. Si vous ne souhaitez pas les supprimer et les conserver dans le fichier, utilisez C<accumulate>.=back=item B<--xlate-update>Cette option force la mise à jour du fichier de cache même si cela n'est pas nécessaire.=back=head1 COMMAND LINE INTERFACEVous pouvez facilement utiliser ce module à partir de la ligne de commande en utilisant la commande C<xlate> incluse dans la distribution. Consultez la page de manuel C<xlate> pour connaître son utilisation.La commande C<xlate> fonctionne en collaboration avec l'environnement Docker, donc même si vous n'avez rien d'installé sous la main, vous pouvez l'utiliser tant que Docker est disponible. Utilisez l'option C<-D> ou C<-C>.De plus, étant donné que des fichiers makefiles pour différents styles de documents sont fournis, la traduction dans d'autres langues est possible sans spécification spéciale. Utilisez l'option C<-M>.Vous pouvez également combiner les options Docker et C<make> afin de pouvoir exécuter C<make> dans un environnement Docker.L'exécution comme C<xlate -C> lancera un shell avec le dépôt git de travail actuel monté.Lisez l'article japonais dans la section L</VOIR AUSSI> pour plus de détails.=head1 EMACSChargez le fichier F<xlate.el> inclus dans le référentiel pour utiliser la commande C<xlate> depuis l'éditeur Emacs. La fonction C<xlate-region> traduit la région donnée. La langue par défaut est C<EN-US> et vous pouvez spécifier la langue en l'appelant avec un argument préfixe.=for html <p><img width="750" src="https://raw.githubusercontent.com/kaz-utashiro/App-Greple-xlate/main/images/emacs.png"></p>=head1 ENVIRONMENT=over 7=item DEEPL_AUTH_KEYDéfinissez votre clé d'authentification pour le service DeepL.=item OPENAI_API_KEYClé d'authentification OpenAI.=back=head1 INSTALL=head2 CPANMINUS$ cpanm App::Greple::xlate=head2 TOOLSVous devez installer les outils en ligne de commande pour DeepL et ChatGPT.=head1 SEE ALSOL<App::Greple::xlate>L<App::Greple::xlate::deepl>L<App::Greple::xlate::gpt3>=over 2=item * L<https://hub.docker.com/r/tecolicom/xlate>Image du conteneur Docker.=item * L<https://github.com/DeepLcom/deepl-python>Bibliothèque DeepL Python et commande CLI.=item * L<https://github.com/openai/openai-python>Bibliothèque Python OpenAI=item * L<https://github.com/tecolicom/App-gpty>Interface en ligne de commande OpenAI=item * L<App::Greple>Consultez le manuel B<greple> pour plus de détails sur le motif de texte cible. Utilisez les options B<--inside>, B<--outside>, B<--include>, B<--exclude> pour limiter la zone de correspondance.=item * L<App::Greple::update>Vous pouvez utiliser le module C<-Mupdate> pour modifier les fichiers en fonction du résultat de la commande B<greple>.=item * L<App::sdif>Utilisez B<sdif> pour afficher le format des marqueurs de conflit côte à côte avec l'option B<-V>.=item * L<App::Greple::stripe>Le module Greple B<stripe> est utilisé par l'option B<--xlate-stripe>.=back=head2 ARTICLES=over 2Module Greple pour traduire et remplacer uniquement les parties nécessaires avec l'API DeepL (en japonais)Génération de documents dans 15 langues avec le module DeepL API (en japonais)Environnement Docker de traduction automatique avec l'API DeepL (en japonais)=back=head1 AUTHORKazumasa Utashiro=head1 LICENSECopyright © 2023-2025 Kazumasa Utashiro.This library is free software; you can redistribute it and/or modifyit under the same terms as Perl itself.=cut
{kind=link}
{kind=link}
{kind=link}
{kind=link}